publications
2026
- PISCES: Annotation-free Text-to-Video Post-Training via Optimal Transport-Aligned RewardsMinh-Quan Le*, Gaurav Mittal*, Cheng Zhao, David Gu, and 2 more authorsIn Forty-Third International Conference on Machine Learning, 2026
Text-to-video (T2V) generation aims to synthesize videos with high visual quality and temporal consistency that are semantically aligned with input text. Reward-based post-training has emerged as a promising direction to improve the quality and semantic alignment of generated videos. However, recent methods either rely on large-scale human preference annotations or operate on misaligned embeddings from pre-trained vision-language models, leading to limited scalability or suboptimal supervision. We present 𝙿𝙸𝚂𝙲𝙴𝚂, an annotation-free post-training algorithm that addresses these limitations via a novel Dual Optimal Transport (OT)-aligned Rewards module. To align reward signals with human judgment, 𝙿𝙸𝚂𝙲𝙴𝚂 uses OT to bridge text and video embeddings at both distributional and discrete token levels, enabling reward supervision to fulfill two objectives: (i) a Distributional OT-aligned Quality Reward that captures overall visual quality and temporal coherence; and (ii) a Discrete Token-level OT-aligned Semantic Reward that enforces semantic, spatio-temporal correspondence between text and video tokens. To our knowledge, 𝙿𝙸𝚂𝙲𝙴𝚂 is the first to improve annotation-free reward supervision in generative post-training through the lens of OT. Experiments on both short- and long-video generation show that 𝙿𝙸𝚂𝙲𝙴𝚂 outperforms both annotation-based and annotation-free methods on VBench across Quality and Semantic scores, with human preference studies further validating its effectiveness. We show that the Dual OT-aligned Rewards module is compatible with multiple optimization paradigms, including direct backpropagation and reinforcement learning fine-tuning.

2025
- What about gravity in video generation? Post-Training Newton’s Laws with Verifiable RewardsMinh-Quan Le, Yuanzhi Zhu, Vicky Kalogeiton, and Dimitris Samaras2025
Recent video diffusion models can synthesize visually compelling clips, yet often violate basic physical laws-objects float, accelerations drift, and collisions behave inconsistently-revealing a persistent gap between visual realism and physical realism. We propose 𝙽𝚎𝚠𝚝𝚘𝚗𝚁𝚎𝚠𝚊𝚛𝚍𝚜, the first physics-grounded post-training framework for video generation based on verifiable rewards. Instead of relying on human or VLM feedback, 𝙽𝚎𝚠𝚝𝚘𝚗𝚁𝚎𝚠𝚊𝚛𝚍𝚜 extracts measurable proxies from generated videos using frozen utility models: optical flow serves as a proxy for velocity, while high-level appearance features serve as a proxy for mass. These proxies enable explicit enforcement of Newtonian structure through two complementary rewards: a Newtonian kinematic constraint enforcing constant-acceleration dynamics, and a mass conservation reward preventing trivial, degenerate solutions. We evaluate 𝙽𝚎𝚠𝚝𝚘𝚗𝚁𝚎𝚠𝚊𝚛𝚍𝚜 on five Newtonian Motion Primitives (free fall, horizontal/parabolic throw, and ramp sliding down/up) using our newly constructed large-scale benchmark, 𝙽𝚎𝚠𝚝𝚘𝚗𝙱𝚎𝚗𝚌𝚑-𝟼𝟶𝙺. Across all primitives in visual and physics metrics, 𝙽𝚎𝚠𝚝𝚘𝚗𝚁𝚎𝚠𝚊𝚛𝚍𝚜 consistently improves physical plausibility, motion smoothness, and temporal coherence over prior post-training methods. It further maintains strong performance under out-of-distribution shifts in height, speed, and friction. Our results show that physics-grounded verifiable rewards offer a scalable path toward physics-aware video generation.
- Hummingbird: High Fidelity Image Generation via Multimodal Context AlignmentMinh-Quan Le*, Gaurav Mittal*, Tianjian Meng, A S M Iftekhar, and 4 more authorsIn The Thirteenth International Conference on Learning Representations, 2025
While diffusion models are powerful in generating high-quality, diverse synthetic data for object-centric tasks, existing methods struggle with scene-aware tasks such as Visual Question Answering (VQA) and Human-Object Interaction (HOI) Reasoning, where it is critical to preserve scene attributes in generated images consistent with a multimodal context, i.e. a reference image with accompanying text guidance query. To address this, we introduce Hummingbird, the first diffusion-based image generator which, given a multimodal context, generates highly diverse images w.r.t. the reference image while ensuring high fidelity by accurately preserving scene attributes, such as object interactions and spatial relationships from the text guidance. Hummingbird employs a novel Multimodal Context Evaluator that simultaneously optimizes our formulated Global Semantic and Fine-grained Consistency Rewards to ensure generated images preserve the scene attributes of reference images in relation to the text guidance while maintaining diversity. As the first model to address the task of maintaining both diversity and fidelity given a multimodal context, we introduce a new benchmark formulation incorporating MME Perception and Bongard HOI datasets. Benchmark experiments show Hummingbird outperforms all existing methods by achieving superior fidelity while maintaining diversity, validating Hummingbird’s potential as a robust multimodal context-aligned image generator in complex visual tasks.
- CamoFA: A Learnable Fourier-based Augmentation for Camouflage SegmentationMinh-Quan Le*, Minh-Triet Tran*, Trung-Nghia Le, Tam V Nguyen, and 1 more authorIn Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2025
Camouflaged object detection (COD) and camouflaged instance segmentation (CIS) aim to recognize and segment objects that are blended into their surroundings, respectively. While several deep neural network models have been proposed to tackle those tasks, augmentation methods for COD and CIS have not been thoroughly explored. Augmentation strategies can help improve the performance of models by increasing the size and diversity of the training data and exposing the model to a wider range of variations in the data. Besides, we aim to automatically learn transformations that help to reveal the underlying structure of camouflaged objects and allow the model to learn to better identify and segment camouflaged objects. To achieve this, we propose a learnable augmentation method in the frequency domain for COD and CIS via Fourier transform approach, dubbed CamoFourier. Our method leverages a conditional generative adversarial network and cross-attention mechanism to generate a reference image and an adaptive hybrid swapping with parameters to mix the low-frequency component of the reference image and the high-frequency component of the input image. This approach aims to make camouflaged objects more visible for detection and segmentation models. Without bells and whistles, our proposed augmentation method boosts the performance of camouflaged object detectors and camouflaged instance segmenters by large margins.
-
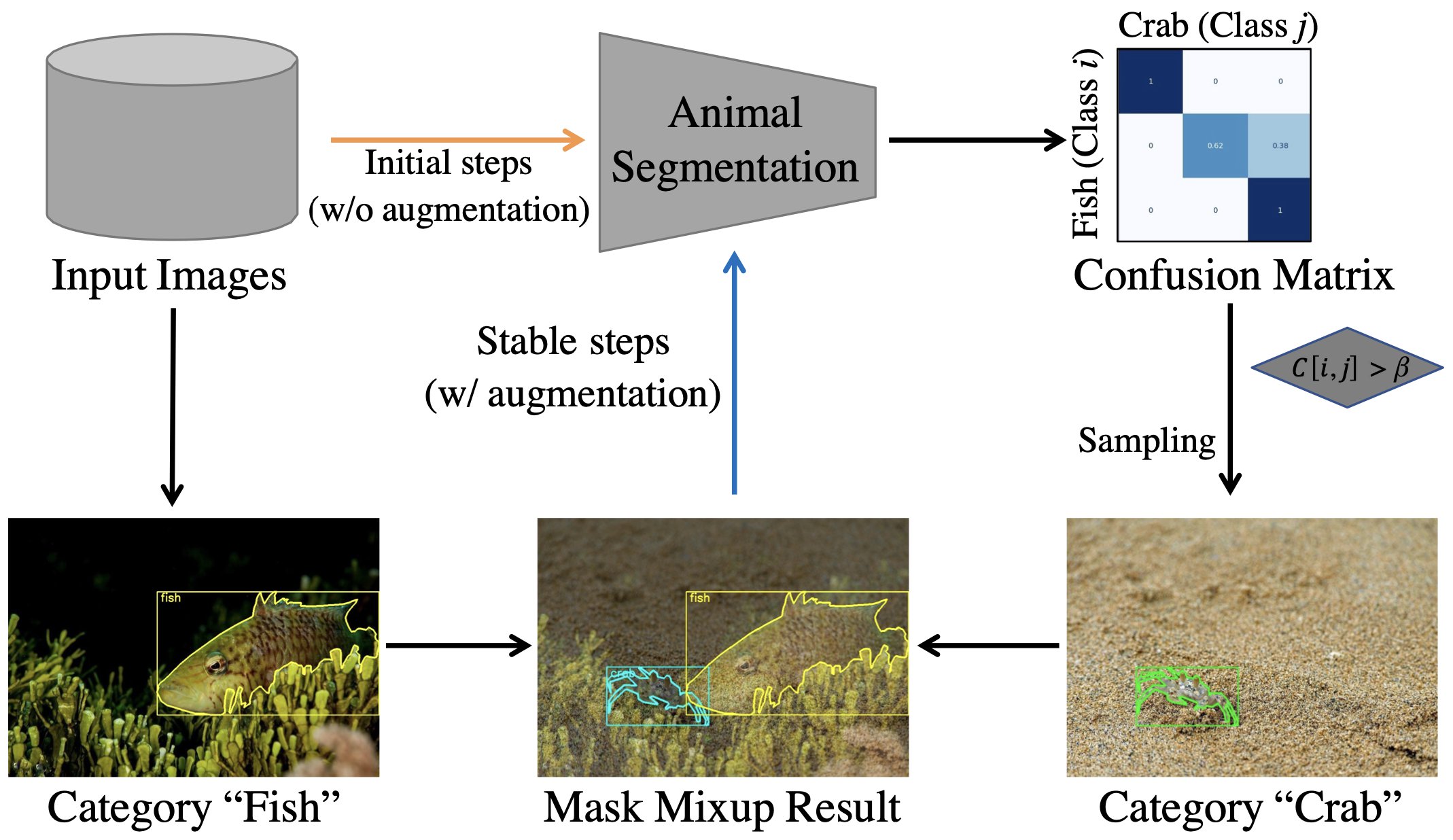 GUNNEL: Guided Mixup Augmentation and Multi-Model Fusion for Aquatic Animal SegmentationMinh-Quan Le*, Trung-Nghia Le*, Tam V Nguyen, Isao Echizen, and 1 more authorNeural Computing and Applications, 2025
GUNNEL: Guided Mixup Augmentation and Multi-Model Fusion for Aquatic Animal SegmentationMinh-Quan Le*, Trung-Nghia Le*, Tam V Nguyen, Isao Echizen, and 1 more authorNeural Computing and Applications, 2025Recent years have witnessed great advances in object segmentation research. In addition to generic objects, aquatic animals have attracted research attention. Deep learning-based methods are widely used for aquatic animal segmentation and have achieved promising performance. However, there is a lack of challenging datasets for benchmarking. In this work, we build a new dataset dubbed Aquatic Animal Species. We also devise a novel GUided mixup augmeNtatioN and multi-modEl fusion for aquatic animaL segmentation (GUNNEL) that leverages the advantages of multiple segmentation models to effectively segment aquatic animals and improves the training performance by synthesizing hard samples. Extensive experiments demonstrated the superiority of our proposed framework over existing state-of-the-art instance segmentation methods. The code is available at https://github.com/lmquan2000/mask-mixup. The dataset is available at https://doi.org/10.5281/zenodo.8208877.




2024
- ∞-Brush: Controllable Large Image Synthesis with Diffusion Models in Infinite DimensionsMinh-Quan Le*, Alexandros Graikos*, Srikar Yellapragada, Rajarsi Gupta, and 2 more authorsIn European Conference on Computer Vision, 2024
Synthesizing high-resolution images from intricate, domain-specific information remains a significant challenge in generative modeling, particularly for applications in large-image domains such as digital histopathology and remote sensing. Existing methods face critical limitations: conditional diffusion models in pixel or latent space cannot exceed the resolution on which they were trained without losing fidelity, and computational demands increase significantly for larger image sizes. Patch-based methods offer computational efficiency but fail to capture long-range spatial relationships due to their overreliance on local information. In this paper, we introduce a novel conditional diffusion model in infinite dimensions, ∞-Brush for controllable large image synthesis. We propose a cross-attention neural operator to enable conditioning in function space. Our model overcomes the constraints of traditional finite-dimensional diffusion models and patch-based methods, offering scalability and superior capability in preserving global image structures while maintaining fine details. To our best knowledge, ∞-Brush is the first conditional diffusion model in function space, that can controllably synthesize images at arbitrary resolutions of up to 4096 x 4096 pixels. The code is available at https://github.com/cvlab-stonybrook/infinity-brush.
- MaskDiff: Modeling Mask Distribution with Diffusion Probabilistic Model for Few-Shot Instance SegmentationMinh-Quan Le, Tam V Nguyen, Trung-Nghia Le, Thanh-Toan Do, and 2 more authorsIn Proceedings of the AAAI Conference on Artificial Intelligence, 2024
Selected as Oral Presentation (top 2.3%).
Few-shot instance segmentation extends the few-shot learning paradigm to the instance segmentation task, which tries to segment instance objects from a query image with a few annotated examples of novel categories. Conventional approaches have attempted to address the task via prototype learning, known as point estimation. However, this mechanism depends on prototypes (e.g. mean of K-shot) for prediction, leading to performance instability. To overcome the disadvantage of the point estimation mechanism, we propose a novel approach, dubbed MaskDiff, which models the underlying conditional distribution of a binary mask, which is conditioned on an object region and K-shot information. Inspired by augmentation approaches that perturb data with Gaussian noise for populating low data density regions, we model the mask distribution with a diffusion probabilistic model. We also propose to utilize classifier-free guided mask sampling to integrate category information into the binary mask generation process. Without bells and whistles, our proposed method consistently outperforms state-of-the-art methods on both base and novel classes of the COCO dataset while simultaneously being more stable than existing methods. The source code is available at: https://github.com/minhquanlecs/MaskDiff.
- Learned representation-guided diffusion models for large-image generationAlexandros Graikos*, Srikar Yellapragada*, Minh-Quan Le, Saarthak Kapse, and 3 more authorsIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
To synthesize high-fidelity samples, diffusion models typically require auxiliary data to guide the generation process. However, it is impractical to procure the painstaking patch-level annotation effort required in specialized domains like histopathology and satellite imagery; it is often performed by domain experts and involves hundreds of millions of patches. Modern-day self-supervised learning (SSL) representations encode rich semantic and visual information. In this paper, we posit that such representations are expressive enough to act as proxies to fine-grained human labels. We introduce a novel approach that trains diffusion models conditioned on embeddings from SSL. Our diffusion models successfully project these features back to high-quality histopathology and remote sensing images. In addition, we construct larger images by assembling spatially consistent patches inferred from SSL embeddings, preserving long-range dependencies. Augmenting real data by generating variations of real images improves downstream classifier accuracy for patch-level and larger, image-scale classification tasks. Our models are effective even on datasets not encountered during training, demonstrating their robustness and generalizability. Generating images from learned embeddings is agnostic to the source of the embeddings. The SSL embeddings used to generate a large image can either be extracted from a reference image, or sampled from an auxiliary model conditioned on any related modality (e.g. class labels, text, genomic data). As proof of concept, we introduce the text-to-large image synthesis paradigm where we successfully synthesize large pathology and satellite images out of text descriptions.



2023
- SketchANIMAR: Sketch-based 3D Animal Fine-Grained RetrievalTrung-Nghia Le, Tam V Nguyen, Minh-Quan Le, Trong-Thuan Nguyen, and 7 more authorsComputers & Graphics, 2023
The retrieval of 3D objects has gained significant importance in recent years due to its broad range of applications in computer vision, computer graphics, virtual reality, and augmented reality. However, the retrieval of 3D objects presents significant challenges due to the intricate nature of 3D models, which can vary in shape, size, and texture, and have numerous polygons and vertices. To this end, we introduce a novel SHREC challenge track that focuses on retrieving relevant 3D animal models from a dataset using sketch queries and expedites accessing 3D models through available sketches. Furthermore, a new dataset named ANIMAR was constructed in this study, comprising a collection of 711 unique 3D animal models and 140 corresponding sketch queries. Our contest requires participants to retrieve 3D models based on complex and detailed sketches. We receive satisfactory results from eight teams and 204 runs. Although further improvement is necessary, the proposed task has the potential to incentivize additional research in the domain of 3D object retrieval, potentially yielding benefits for a wide range of applications. We also provide insights into potential areas of future research, such as improving techniques for feature extraction and matching and creating more diverse datasets to evaluate retrieval performance.
- TextANIMAR: Text-based 3D Animal Fine-Grained RetrievalTrung-Nghia Le, Tam V Nguyen, Minh-Quan Le, Trong-Thuan Nguyen, and 7 more authorsComputers & Graphics, 2023
3D object retrieval is an important yet challenging task that has drawn more and more attention in recent years. While existing approaches have made strides in addressing this issue, they are often limited to restricted settings such as image and sketch queries, which are often unfriendly interactions for common users. In order to overcome these limitations, this paper presents a novel SHREC challenge track focusing on text-based fine-grained retrieval of 3D animal models. Unlike previous SHREC challenge tracks, the proposed task is considerably more challenging, requiring participants to develop innovative approaches to tackle the problem of text-based retrieval. Despite the increased difficulty, we believe this task can potentially drive useful applications in practice and facilitate more intuitive interactions with 3D objects. Five groups participated in our competition, submitting a total of 114 runs. While the results obtained in our competition are satisfactory, we note that the challenges presented by this task are far from fully solved. As such, we provide insights into potential areas for future research and improvements. We believe we can help push the boundaries of 3D object retrieval and facilitate more user-friendly interactions via vision-language technologies.
-
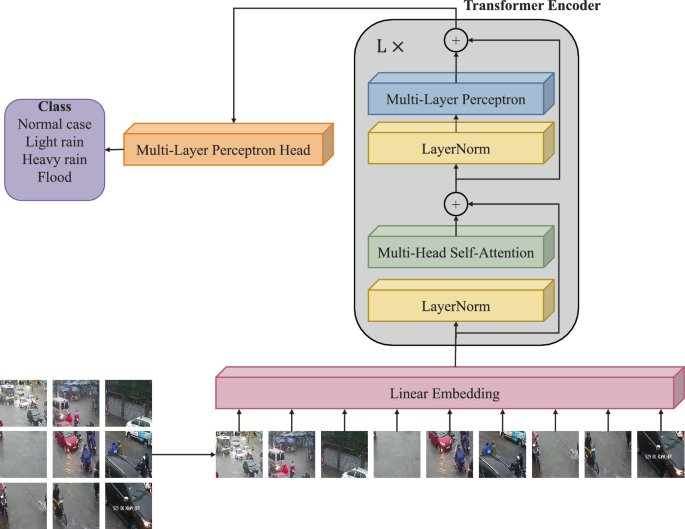 FL-Former: Flood Level Estimation with Vision Transformer for Images from Cameras in Urban AreasQuoc-Cuong Le, Minh-Quan Le, Mai-Khiem Tran, Ngoc-Quyen Le, and 1 more authorIn International Conference on Multimedia Modeling, 2023
FL-Former: Flood Level Estimation with Vision Transformer for Images from Cameras in Urban AreasQuoc-Cuong Le, Minh-Quan Le, Mai-Khiem Tran, Ngoc-Quyen Le, and 1 more authorIn International Conference on Multimedia Modeling, 2023Flooding in urban areas is one of the serious problems and needs special attention in urban development and improving people’s living quality. Flood detection to promptly provide data for hydrometeorological forecasting systems will help make timely forecasts for life. In addition, providing information about rain and flooding in many locations in the city will help people make appropriate decisions about traffic. Therefore, in this paper, we present our FL-Former solution for detecting and classifying rain and inundation levels in urban locations, specifically in Ho Chi Minh City, based on images recorded from cameras using Vision Transformer. We also build the HCMC-URF dataset with more than 10 K images of various rainy and flooding conditions in Ho Chi Minh City to serve the community’s research. Finally, we propose the software architecture and construction of an online API system to provide timely information about rain and flooding at several locations in the city as extra input for hydrometeorological analysis and prediction systems, as well as provide information to citizens via mobile or web applications.



2022
-
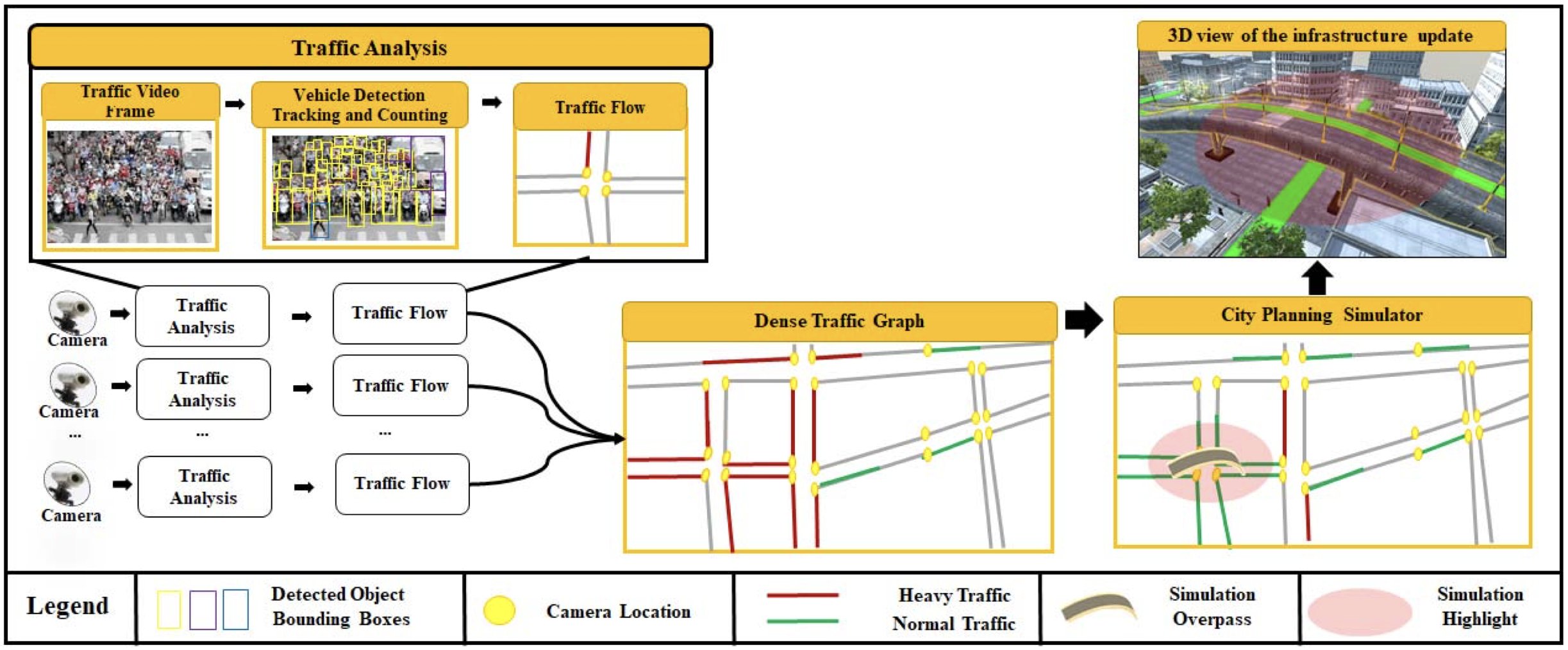 Data-Driven City Traffic Planning SimulationTam V Nguyen, Thanh Ngoc-Dat Tran, Viet-Tham Huynh, Bao Truong, and 5 more authorsIn 2022 IEEE International Symposium on Mixed and Augmented Reality Adjunct (ISMAR-Adjunct), 2022
Data-Driven City Traffic Planning SimulationTam V Nguyen, Thanh Ngoc-Dat Tran, Viet-Tham Huynh, Bao Truong, and 5 more authorsIn 2022 IEEE International Symposium on Mixed and Augmented Reality Adjunct (ISMAR-Adjunct), 2022Big cities are well-known for their traffic congestion and high density of vehicles such as cars, buses, trucks, and even a swarm of motorbikes that overwhelm city streets. Large-scale development projects have exacerbated urban conditions, making traffic congestion more severe. In this paper, we proposed a data-driven city traffic planning simulator. In particular, we make use of the city camera system for traffic analysis. It seeks to recognize the traffic vehicles and traffic flows, with reduced intervention from monitoring staff. Then, we develop a city traffic planning simulator upon the analyzed traffic data. The simulator is used to support metropolitan transportation planning. Our experimental findings address traffic planning challenges and the innovative technical solutions needed to solve them in big cities.
- SHREC 2022 Track on Online Detection of Heterogeneous GesturesMarco Emporio, Ariel Caputo, Andrea Giachetti, Marco Cristani, and 7 more authorsComputers & Graphics, 2022
This paper presents the outcomes of a contest organized to evaluate methods for the online recognition of heterogeneous gestures from sequences of 3D hand poses. The task is the detection of gestures belonging to a dictionary of 16 classes characterized by different pose and motion features. The dataset features continuous sequences of hand tracking data where the gestures are interleaved with non-significant motions. The data have been captured using the Hololens 2 finger tracking system in a realistic use-case of mixed reality interaction. The evaluation is based not only on the detection performances but also on the latency and the false positives, making it possible to understand the feasibility of practical interaction tools based on the algorithms proposed. The outcomes of the contest’s evaluation demonstrate the necessity of further research to reduce recognition errors, while the computational cost of the algorithms proposed is sufficiently low.
-
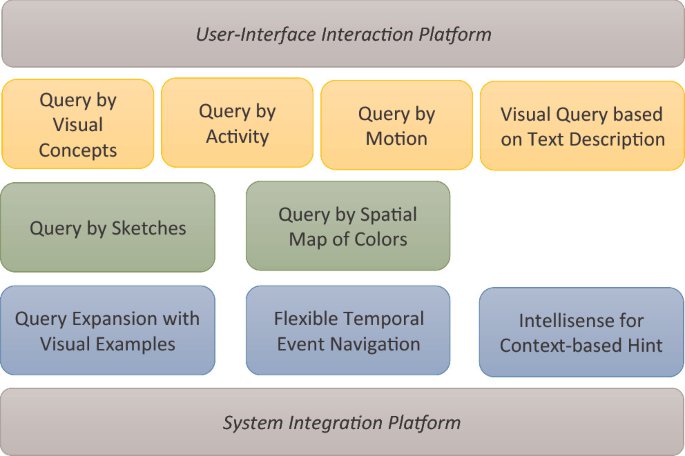 V-FIRST: A Flexible Interactive Retrieval System for Video at VBS 2022Minh-Triet Tran, Nhat Hoang-Xuan, Hoang-Phuc Trang-Trung, Thanh-Cong Le, and 5 more authorsIn International Conference on Multimedia Modeling, 2022
V-FIRST: A Flexible Interactive Retrieval System for Video at VBS 2022Minh-Triet Tran, Nhat Hoang-Xuan, Hoang-Phuc Trang-Trung, Thanh-Cong Le, and 5 more authorsIn International Conference on Multimedia Modeling, 2022Video retrieval systems have a wide range of applications across multiple domains, therefore the development of user-friendly and efficient systems is necessary. For VBS 2022, we develop a flexible interactive system for video retrieval, namely V-FIRST, that supports two scenarios of usage: query with text descriptions and query with visual examples. We take advantage of both visual and temporal information from videos to extract concepts related to entities, events, scenes, activities, and motion trajectories for video indexing. Our system supports queries with keywords and sentence descriptions as V-FIRST can evaluate the semantic similarities between visual and textual embedding vectors. V-FIRST also allows users to express queries with visual impressions, such as sketches and 2D spatial maps of dominant colors. We use query expansion, elastic temporal video navigation, and intellisense for hints to further boost the performance of our system.



2021
-
 Camouflaged Instance Segmentation In-the-Wild: Dataset, Method, and Benchmark SuiteTrung-Nghia Le, Yubo Cao, Tan-Cong Nguyen, Minh-Quan Le, and 4 more authorsIEEE Transactions on Image Processing, 2021
Camouflaged Instance Segmentation In-the-Wild: Dataset, Method, and Benchmark SuiteTrung-Nghia Le, Yubo Cao, Tan-Cong Nguyen, Minh-Quan Le, and 4 more authorsIEEE Transactions on Image Processing, 2021This paper pushes the envelope on decomposing camouflaged regions in an image into meaningful components, namely, camouflaged instances. To promote the new task of camouflaged instance segmentation of in-the-wild images, we introduce a dataset, dubbed CAMO++, that extends our preliminary CAMO dataset (camouflaged object segmentation) in terms of quantity and diversity. The new dataset substantially increases the number of images with hierarchical pixel-wise ground truths. We also provide a benchmark suite for the task of camouflaged instance segmentation. In particular, we present an extensive evaluation of state-of-the-art instance segmentation methods on our newly constructed CAMO++ dataset in various scenarios. We also present a camouflage fusion learning (CFL) framework for camouflaged instance segmentation to further improve the performance of state-of-the-art methods. The dataset, model, evaluation suite, and benchmark will be made publicly available on our project page.
- SHREC 2021: Skeleton-based Hand Gesture Recognition in the WildAriel Caputo, Andrea Giachetti, Simone Soso, Deborah Pintani, and 7 more authorsComputers & Graphics, 2021
Gesture recognition is a fundamental tool to enable novel interaction paradigms in a variety of application scenarios like Mixed Reality environments, touchless public kiosks, entertainment systems, and more. Recognition of hand gestures can be nowadays performed directly from the stream of hand skeletons estimated by software provided by low-cost trackers (Ultraleap) and MR headsets (Hololens, Oculus Quest) or by video processing software modules (e.g. Google Mediapipe). Despite the recent advancements in gesture and action recognition from skeletons, it is unclear how well the current state-of-the-art techniques can perform in a real-world scenario for the recognition of a wide set of heterogeneous gestures, as many benchmarks do not test online recognition and use limited dictionaries. This motivated the proposal of the SHREC 2021: Track on Skeleton-based Hand Gesture Recognition in the Wild. For this contest, we created a novel dataset with heterogeneous gestures featuring different types and duration. These gestures have to be found inside sequences in an online recognition scenario. This paper presents the result of the contest, showing the performances of the techniques proposed by four research groups on the challenging task compared with a simple baseline method.
- Interactive Video Object Mask AnnotationTrung-Nghia Le, Tam V Nguyen, Quoc-Cuong Tran, Lam Nguyen, and 3 more authorsIn Proceedings of the AAAI Conference on Artificial Intelligence, 2021
In this paper, we introduce a practical system for interactive video object mask annotation, which can support multiple back-end methods. To demonstrate the generalization of our system, we introduce a novel approach for video object annotation. Our proposed system takes scribbles at a chosen key-frame from the end-users via a user-friendly interface and produces masks of corresponding objects at the key-frame via the Control-Point-based Scribbles-to-Mask (CPSM) module. The object masks at the key-frame are then propagated to other frames and refined through the Multi-Referenced Guided Segmentation (MRGS) module. Last but not least, the user can correct wrong segmentation at some frames, and the corrected mask is continuously propagated to other frames in the video via the MRGS to produce the object masks at all video frames.



2020
- SHREC 2020: Retrieval of Digital Surfaces with Similar Geometric ReliefsElia Moscoso Thompson, Silvia Biasotti, Andrea Giachetti, Claudio Tortorici, and 7 more authorsComputers & Graphics, 2020
This paper presents the methods that have participated in the SHREC’20 contest on retrieval of surface patches with similar geometric reliefs and the analysis of their performance over the benchmark created for this challenge. The goal of the context is to verify the possibility of retrieving 3D models only based on the reliefs that are present on their surface and to compare methods that are suitable for this task. This problem is related to many real world applications, such as the classification of cultural heritage goods or the analysis of different materials. To address this challenge, it is necessary to characterize the local ”geometric pattern” information, possibly forgetting model size and bending. Seven groups participated in this contest and twenty runs were submitted for evaluation. The performances of the methods reveal that good results are achieved with a number of techniques that use different approaches.
-
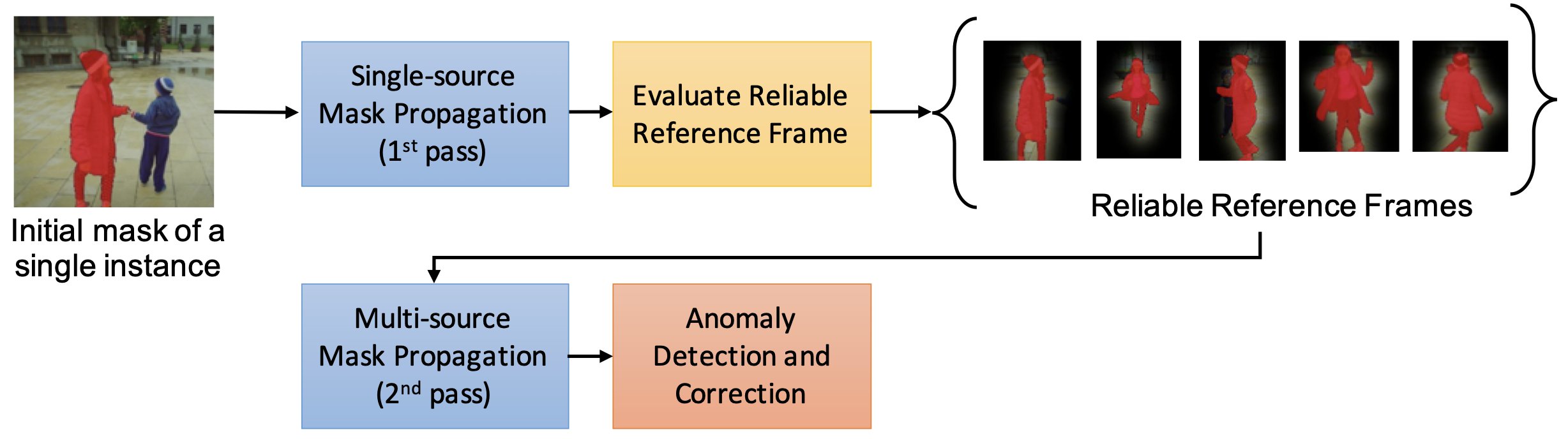 Multi-Referenced Guided Instance Segmentation Framework for Semi-supervised Video Instance SegmentationMinh-Triet Tran, T Hoang, Tam V Nguyen, Trung-Nghia Le, and 5 more authorsIn CVPR Workshops, 2020
Multi-Referenced Guided Instance Segmentation Framework for Semi-supervised Video Instance SegmentationMinh-Triet Tran, T Hoang, Tam V Nguyen, Trung-Nghia Le, and 5 more authorsIn CVPR Workshops, 2020In this paper, we propose a novel Multi-Referenced Guided Instance Segmentation (MR-GIS) framework for the challenging problem of semi-supervised video instance seg-mentation. Our proposed method consists two passes of segmentation with mask guidance. First, we quickly propagate an initial mask to all frames in a sequence to create an initial segmentation result of the instance. Second, we re-propagate masks with reference to multiple extra samples. We put high confidence reliable frames in the memory pool for reference, namely Reliable Extra Samples. To enhance the consistency of instance masks across frames, we search for mask anomaly in consecutive frames and correct them. Our proposed MR-GIS achieves 76.5, 82.1, and 79.3 in terms of region similarity (J), contour accuracy (F), and global score, respectively, on DAVIS 2020 Challenge dataset, rank 4th in the challenge on semi-supervised task.
-
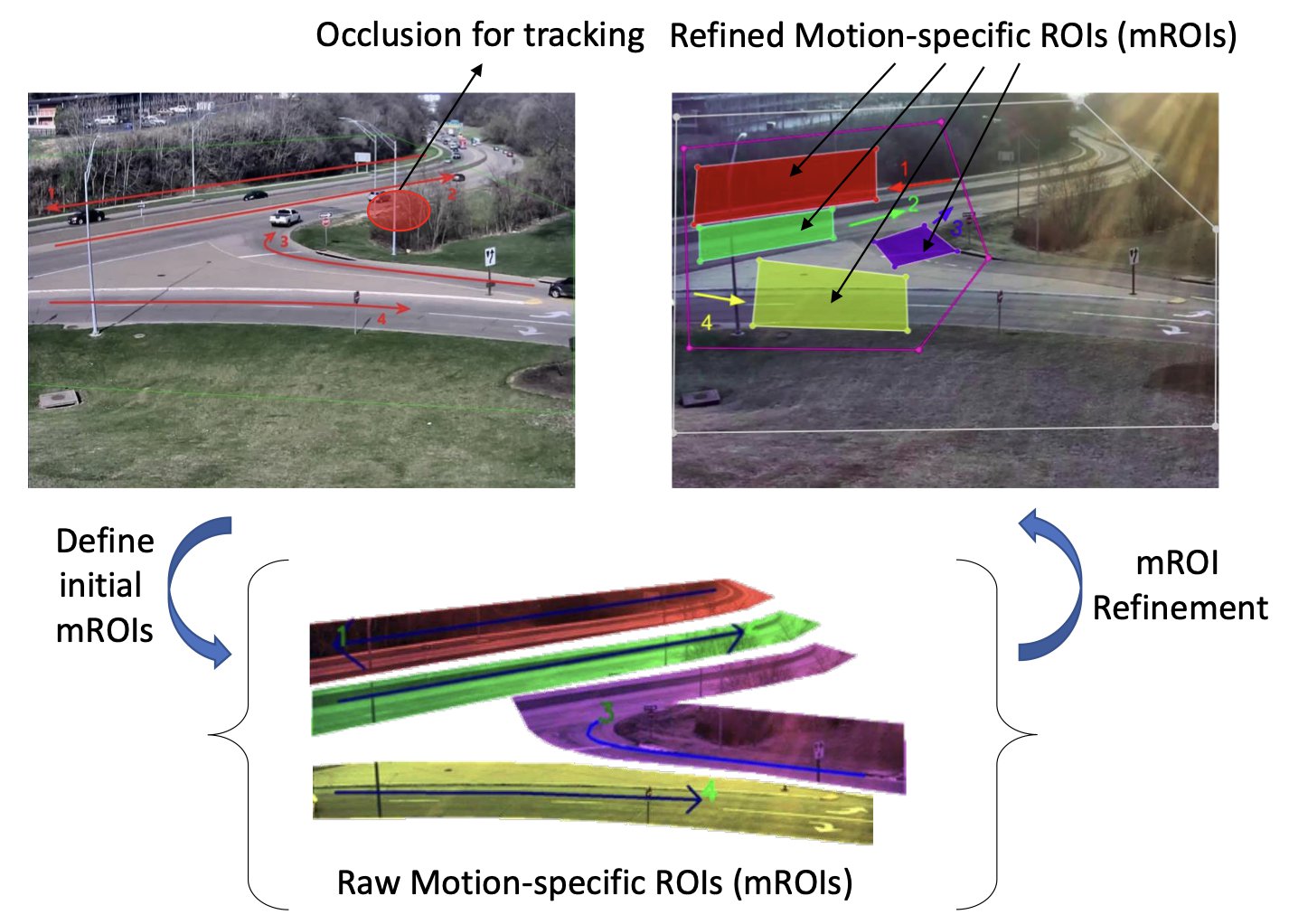 iTASK - Intelligent Traffic Analysis Software KitMinh-Triet Tran, Tam V Nguyen, Trung-Hieu Hoang, Trung-Nghia Le, and 7 more authorsIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2020
iTASK - Intelligent Traffic Analysis Software KitMinh-Triet Tran, Tam V Nguyen, Trung-Hieu Hoang, Trung-Nghia Le, and 7 more authorsIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2020Traffic flow analysis is essential for intelligent transportation systems. In this paper, we introduce our Intelligent Traffic Analysis Software Kit (iTASK) to tackle three challenging problems: vehicle flow counting, vehicle re-identification, and abnormal event detection. For the first problem, we propose to real-time track vehicles moving along the desired direction in corresponding motion-of-interests (MOIs). For the second problem, we consider each vehicle as a document with multiple semantic words (i.e., vehicle attributes) and transform the given problem to classical document retrieval. For the last problem, we propose to forward and backward refine anomaly detection using GAN-based future prediction and backward tracking completely stalled vehicle or sudden-change direction, respectively. Experiments on the datasets of traffic flow analysis from AI City Challenge 2020 show our competitive results, namely, S1 score of 0.8297 for vehicle flow counting in Track 1, mAP score of 0.3882 for vehicle re-identification in Track 2, and S4 score of 0.9059 for anomaly detection in Track 4. All data and source code are publicly available on our project page.


